Large Language Models (LLMs) have shown outstanding ability in questioning-answering tasks. Yet, plain answers may not be the preferred outcome for education. Effective educators seek to encourage students to discover the answers to their questions by their means. We inspire our work from the Socratic Method famously showcased in Plato’s Republic. Here, Socrates questions Cephalus about the meaning of justice. When Cephalus defines justice as telling the truth and repaying debts, Socrates counters with a scenario that tests this idea, prompting Cephalus to review his definition.
We are fine-tuning LLMs to act more like Socratic tutors. Instead of just giving plain answers, our models ask probing questions to encourage students to think critically and deepen their understanding of the selected topic. For example, instead of providing the solution to \(x^2−4=0\), the model prompts the student to factor the equation and find the values of \(x\) that solve it.
We use Direct Preference Optimization (DPO) to instruct LLMs to follow the Socratic Method. DPO is a widely used technique for aligning LLMs to human preferences. We generate diverse datasets and train the LLM to judge and rank answers based on their educational value. Our fine-tuned models perform much better than the originals, increasing their educational value.
Evaluation metric
Defining the “socrativeness” of interactions is challenging. Therefore, we break the evaluation into four different aspects:
- questions: a boolean score that should be True if the answer contains at least a question turned to the student, False otherwise.
- on topic: a score on a scale from 1 (completely off-topic) to 5 (perfectly on-topic), which measures how much the teacher’s answer is relevant to the ongoing conversation.
- helpful: a score on a scale from 1 (completely unhelpful) to 5 (very helpful), which measures the usefulness of the response in providing guidance and support to the student.
- reveal answer: a boolean score that should be True if the teacher’s answer directly reveals the correct answer (which we want to penalize), False otherwise.
We ask a GPT-4o (i.e., LLM-as-a-judge) to evaluate interactions according to these four characteristics (check out the prompt here). These four aspects are then uniformly weighed and normalized into a numerical summary score, ranging from zero to one.
To validate GPT-4o assessments, we compare them to those of human annotators for a set of 100 examples. We found a strong Pearson correlation (\(p=0.78\)) and aligned choices for the four components between GPT-4os and those of human annotators.


Training Pipeline
There are many ways to steer LLMs to specific behaviors. Our choice of method is Direct Preference Optimization (DPO). DPO maximizes the likelihood of a user-defined set of “good” examples while minimizing the likelihood of “bad” examples. It has two main advantages: First, it has a low memory footprint, requiring just a reference model and the training model to execute; Secondly, it is a more stable algorithm and easier to tune than its counterparts.
As a choice of model, we fine-tune Phi-3-Mini-4k-Instruct, one of the small-size state-of-the-art LLMs (3.8 billion parameters). This model is already fine-tuned for the following instructions, thus simplifying the training procedure since we can request it to behave according to the Socratic method with prompt engineering.
We follow the procedure illustrated below.
- We generate with five candidate answers (Answer A to Answer E) for each input using this prompt;
- We use GPT-4o as a judge to assess the adherence of interactions to the Socratic method based on four criteria;
- For each example, we extract a final summarized score ranging from zero to one, where one is the best outcome;
- We select the best example (highest score) to be the accepted answer and the worst example (lowest score) as the rejected answer;
- We perform training on the base model with DPO.

Results & Analysis
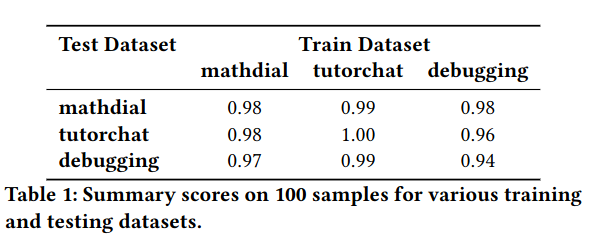
We fine-tuned three models over three different datasets (Debugging, MathDial, and TutorChat). All these three datasets were designed to contain examples of high-quality Socratic interactions.
We observe that the model trained on TutorChat is the most performing, yielding good performance on all three datasets. Notably, the TutorChat-trained model surpasses the models trained on MathDial and Debugging when evaluated on their respective test sets, albeit by a small margin. Such an effect is likely due to the preference dataset of TutorChat, which indicates a higher data diversity than the MathDial and Debugging datasets.
Below, we present the mean summary scores over the 100 samples for the TutorChat fine-tuned model and the base model using only prompt engineering. We add GPT-4o’s performance with only prompt engineering to provide a reference of the best possible performance with prompt engineering-only strategies. The fine-tuned model improved significantly over the base model, reaching close performance to a much larger and more powerful GPT-4o in all datasets.

The TutorChat-trained model (our best model) showed significant gains in three key areas and now performs almost as well as GPT-4o. This also shows the model’s strong generalization ability, as it was trained on TutorChat data but excelled on the different MathDial datasets.

It also showed significant gains in three areas, nearing GPT-4o performance, and demonstrated strong generalization by excelling on a dataset different from its training data.
Conclusions
Fine-tuning Large Language Models (LLMs) with Direct Preference Optimization enhances their performance in educational settings, especially when using the Socratic Method. These fine-tuned models better promote critical thinking by asking guiding questions instead of giving plain answers.
Future work will focus on using more powerful models and refining our metric system by adding more evaluation aspects. Larger models could improve the accuracy and effectiveness of Socratic dialogues, creating even more robust educational tools.
Lastly, we disclose that this work is only a part of a larger educational project. At EURECOM, we are developing chatbots to help students with learning activities. Our chatbots can address the students’ questions while searching through educational content from our institution (such as textbooks, slides, and lecture handouts). You can experiment chatting with EULER.
And do not forget to try out our Socratic model at HuggingFace or Ollama!